Archiving WordPress MU blogs to browsable format
![]() Mikael Willberg
Mikael Willberg
![]() 4.5.2010
4.5.2010![]() English, Suomi
English, Suomi![]() Projects · Hacking
Projects · Hacking![]() Wordpress
Wordpress
I faced a situation in which I had to archive few hundred blogs to browsable format from WordPress MU (multi-user) server. The server was configured to allow only secure https connections. This seemed an easy task, but reality was a bit different...
Natural solution was to use wget utility, but I just ended up with files that indicated a need to authenticate to every blog. I also rechecked that the blogs were to to be public. I think this is the same issue that Andrew Harvey experienced: Saving the WordPress.com Export File and The Linked Media Files (and wget’s strictness). I also tried some windows based tools like httrack, but they produced the same result or did not have SSL support.
I think the problem is that wget obeys RFC to the letter which complicates things a lot. In this case the reason was that the authentication cookie was "locked" to certain path even thought it worked on every path on server. I did now want to recompile wget to remove that annoyance and at last I figured a way to do this, after a lot of frustration if I might add.
Solution
The following procedure should work also with a standard WordPress site.
1. Create a dummy user to the WPMU.
2. Login with that user.
3. Extract "wordpressuser" and "wordpresspass" cookie content values. Remember to check the server and path as there might be a lot of these.
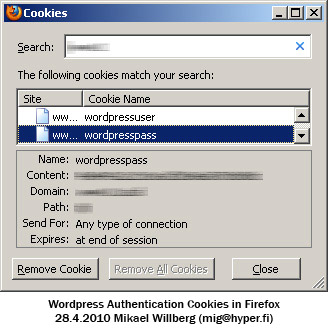
Firefox users can also use Cookie Exporter plugin to dump all cookies to a file and copy the relevant values from there.
4. Use wget to do the actual archiving. Here is the complete command.
wget -m -nv -x -k -K -e robots=off -E --ignore-length --no-check-certificate -np --cookies=off --header "Cookie: wordpressuser=USERNAME;wordpresspass=ENCODEDPASSWORD" -U "IE6 on Windows XP: Mozilla/4.0 (compatible; MSIE 6.0; Microsoft Windows NT 5.1)" https://WEBSITE/PATH/
Most likely you want to use the following table to decipher what settings I used.
| -m | Turn on options suitable for mirroring. This option turns on recursion and time-stamping, sets infinite recursion depth and keeps ftp directory listings. It is currently equivalent to ‘-r -N -l inf --no-remove-listing’. |
| -nv | Turn off verbose without being completely quiet (use ‘-q’ for that), which means that error messages and basic information still get printed. |
| -x | The opposite of ‘-nd’—create a hierarchy of directories, even if one would not have been created otherwise. |
| -k | After the download is complete, convert the links in the document to make them suitable for local viewing. |
| -K | When converting a file, back up the original version with a ‘.orig’ suffix. |
| -e robots=off | Specify whether the norobots convention is respected by Wget, “on” by default. This switch controls both the /robots.txt and the ‘nofollow’ aspect of the spec. |
| -E | If a file of type ‘application/xhtml+xml’ or ‘text/html’ is downloaded and the URL does not end with the regexp ‘\.[Hh][Tt][Mm][Ll]?’, this option will cause the suffix ‘.html’ to be appended to the local filename. |
| --ignore-length | With this option, Wget will ignore the Content-Length header—as if it never existed. |
| --no-check-certificate | Don't check the server certificate against the available certificate authorities. Also don't require the URL host name to match the common name presented by the certificate. |
| -np | Do not ever ascend to the parent directory when retrieving recursively. |
| --cookies=off | Disable the use of cookies. |
| --header | Send header-line along with the rest of the headers in each http request. |
| -U | Identify as agent-string to the http server. |
Problems
When the command completes and there are still files like "wp-login.php@redirect_to=%2Ffoo%2Fbar%2F.html" the defined cookie credentials are incorrect, for at least to that path. Maybe that path should be archived separately using different cookie values.